import pandas as pdThis is the script I used to import my data using the MET API. I am including it here as plain text so that the code won’t execute when I run and publish the notebook.
import requests
import json
url = "https://collectionapi.metmuseum.org/public/collection/v1/search"
params = {'q': 'woman'}
r = requests.get(url, params=params)
parsed = r.json()
ids = parsed['objectIDs']
objects = []
for i in ids[:500]:
url = f"https://collectionapi.metmuseum.org/public/collection/v1/objects/{i}"
r = requests.get(url)
parsed = r.json()
objects.append(parsed)
with open("woman_500.json", "w") as f:
json.dump(objects, f)# import the above script
df = pd.read_csv('https://bit.ly/664-met-woman')dfviewing data¶
data overviews, start & end:
df.info(),df.head(),df.tail()attributes:
df.shape,df.columns()selecting columns:
df['column_name'],df.column_nameseeing values:
df['column_name'].valuesslicing rows:
df['0:3']statistics:
df.describe()
data overviews, start & end¶
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 500 entries, 0 to 499
Data columns (total 59 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 500 non-null int64
1 objectID 492 non-null float64
2 isHighlight 492 non-null float64
3 accessionNumber 492 non-null object
4 accessionYear 489 non-null float64
5 isPublicDomain 492 non-null float64
6 primaryImage 415 non-null object
7 primaryImageSmall 415 non-null object
8 additionalImages 492 non-null object
9 constituents 129 non-null object
10 department 492 non-null object
11 objectName 491 non-null object
12 title 492 non-null object
13 culture 283 non-null object
14 period 348 non-null object
15 dynasty 66 non-null object
16 reign 26 non-null object
17 portfolio 0 non-null float64
18 artistRole 129 non-null object
19 artistPrefix 7 non-null object
20 artistDisplayName 129 non-null object
21 artistDisplayBio 122 non-null object
22 artistSuffix 1 non-null object
23 artistAlphaSort 129 non-null object
24 artistNationality 120 non-null object
25 artistBeginDate 123 non-null object
26 artistEndDate 123 non-null object
27 artistGender 11 non-null object
28 artistWikidata_URL 118 non-null object
29 artistULAN_URL 120 non-null object
30 objectDate 491 non-null object
31 objectBeginDate 492 non-null float64
32 objectEndDate 492 non-null float64
33 medium 492 non-null object
34 dimensions 492 non-null object
35 measurements 456 non-null object
36 creditLine 492 non-null object
37 geographyType 99 non-null object
38 city 7 non-null object
39 state 2 non-null object
40 county 0 non-null float64
41 country 88 non-null object
42 region 38 non-null object
43 subregion 38 non-null object
44 locale 23 non-null object
45 locus 13 non-null object
46 excavation 26 non-null object
47 river 0 non-null float64
48 classification 394 non-null object
49 rightsAndReproduction 26 non-null object
50 linkResource 0 non-null float64
51 metadataDate 492 non-null object
52 repository 492 non-null object
53 objectURL 492 non-null object
54 tags 422 non-null object
55 objectWikidata_URL 458 non-null object
56 isTimelineWork 492 non-null float64
57 GalleryNumber 443 non-null object
58 message 8 non-null object
dtypes: float64(11), int64(1), object(47)
memory usage: 230.6+ KB
attributes¶
df.shape(500, 59)df.columnsIndex(['Unnamed: 0', 'objectID', 'isHighlight', 'accessionNumber',
'accessionYear', 'isPublicDomain', 'primaryImage', 'primaryImageSmall',
'additionalImages', 'constituents', 'department', 'objectName', 'title',
'culture', 'period', 'dynasty', 'reign', 'portfolio', 'artistRole',
'artistPrefix', 'artistDisplayName', 'artistDisplayBio', 'artistSuffix',
'artistAlphaSort', 'artistNationality', 'artistBeginDate',
'artistEndDate', 'artistGender', 'artistWikidata_URL', 'artistULAN_URL',
'objectDate', 'objectBeginDate', 'objectEndDate', 'medium',
'dimensions', 'measurements', 'creditLine', 'geographyType', 'city',
'state', 'county', 'country', 'region', 'subregion', 'locale', 'locus',
'excavation', 'river', 'classification', 'rightsAndReproduction',
'linkResource', 'metadataDate', 'repository', 'objectURL', 'tags',
'objectWikidata_URL', 'isTimelineWork', 'GalleryNumber', 'message'],
dtype='object')dropping columns¶
# let's drop the "Unnamed" column
df = df.drop('Unnamed: 0', axis=1)df.columnsIndex(['objectID', 'isHighlight', 'accessionNumber', 'accessionYear',
'isPublicDomain', 'primaryImage', 'primaryImageSmall',
'additionalImages', 'constituents', 'department', 'objectName', 'title',
'culture', 'period', 'dynasty', 'reign', 'portfolio', 'artistRole',
'artistPrefix', 'artistDisplayName', 'artistDisplayBio', 'artistSuffix',
'artistAlphaSort', 'artistNationality', 'artistBeginDate',
'artistEndDate', 'artistGender', 'artistWikidata_URL', 'artistULAN_URL',
'objectDate', 'objectBeginDate', 'objectEndDate', 'medium',
'dimensions', 'measurements', 'creditLine', 'geographyType', 'city',
'state', 'county', 'country', 'region', 'subregion', 'locale', 'locus',
'excavation', 'river', 'classification', 'rightsAndReproduction',
'linkResource', 'metadataDate', 'repository', 'objectURL', 'tags',
'objectWikidata_URL', 'isTimelineWork', 'GalleryNumber', 'message'],
dtype='object')# let's drop some more columns
unwanted_columns = ['primaryImageSmall', 'portfolio', 'artistRole', 'artistPrefix', 'artistSuffix', 'artistAlphaSort', 'subregion', 'locale', 'locus', 'excavation', 'river', 'classification', 'rightsAndReproduction', 'linkResource', 'metadataDate', 'repository']
for item in unwanted_columns:
df = df.drop(item, axis=1)df.columnsIndex(['objectID', 'isHighlight', 'accessionNumber', 'accessionYear',
'isPublicDomain', 'primaryImage', 'additionalImages', 'constituents',
'department', 'objectName', 'title', 'culture', 'period', 'dynasty',
'reign', 'artistDisplayName', 'artistDisplayBio', 'artistNationality',
'artistBeginDate', 'artistEndDate', 'artistGender',
'artistWikidata_URL', 'artistULAN_URL', 'objectDate', 'objectBeginDate',
'objectEndDate', 'medium', 'dimensions', 'measurements', 'creditLine',
'geographyType', 'city', 'state', 'county', 'country', 'region',
'objectURL', 'tags', 'objectWikidata_URL', 'isTimelineWork',
'GalleryNumber', 'message'],
dtype='object')selecting columns & their values¶
df['title']0 Woman
1 Woman
2 Terracotta lekythos (oil flask)
3 Woman
4 Woman
...
495 Abduction of a Sabine Woman
496 Susannah and the Elders before Daniel
497 Terracotta alabastron (perfume vase) in the fo...
498 Sa Amulet
499 The Thrown Kiss
Name: title, Length: 500, dtype: object# this is a 'Series' type of object
type(df['title'])pandas.core.series.Seriesdf['medium']0 Oil and charcoal on canvas
1 Hard-paste porcelain
2 Terracotta
3 Gelatin silver print
4 Oil paint with collage of cut and printed pape...
...
495 Bronze; on non-contemporary marble pedestal (r...
496 Pen and brown ink, brush and brown wash, highl...
497 Terracotta
498 Silver, electrum
499 Hard-paste porcelain
Name: medium, Length: 500, dtype: objectdf['medium'].values[:30]array(['Oil and charcoal on canvas', 'Hard-paste porcelain', 'Terracotta',
'Gelatin silver print',
'Oil paint with collage of cut and printed paper on board', nan,
'Pastel on flocked paper', 'Oil on paper, mounted on cardboard',
'Lithograph',
'Gelatin silver print in original frame of glass, tape, cardboard, string',
nan, 'Stained wood', 'Bronze', 'Charcoal over graphite on paper',
nan,
'Polychromed terracotta head and wooden limbs; body of wire wrapped in tow; various fabrics and lace',
'Soft-paste porcelain', 'Ivory', 'Hard-paste biscuit porcelain',
'Hard-paste porcelain', 'Hard-paste porcelain',
'Hard-paste porcelain',
'Pastel on light green wove paper, now discolored to warm gray, affixed to original pulpboard mount',
'Bronze', nan, 'Travertine (Egyptian alabaster), steatite',
'Cartonnage, paint', 'Marble, Pentelic', 'Oil on canvas',
'Walnut, polychromy and gilding'], dtype=object)# what is a numpy object?
type(df['medium'].values)numpy.ndarraydf.title0 Woman
1 Woman
2 Terracotta lekythos (oil flask)
3 Woman
4 Woman
...
495 Abduction of a Sabine Woman
496 Susannah and the Elders before Daniel
497 Terracotta alabastron (perfume vase) in the fo...
498 Sa Amulet
499 The Thrown Kiss
Name: title, Length: 500, dtype: objectdf.title.values[:30]array(['Woman', 'Woman', 'Terracotta lekythos (oil flask)', 'Woman',
'Woman', nan, 'Woman', 'Woman', 'Woman', 'Woman', nan, 'Woman',
'Woman', 'Woman', nan, 'Woman', 'Woman', 'Woman', 'Woman', 'Woman',
'Woman', 'Woman', 'Woman Having Her Hair Combed', 'Standing Woman',
nan,
'Cosmetic Spoon in the Shape of Swimming Woman Holding a Dish',
'Cartonnage of a Woman',
'Marble grave stele of a young woman and servant',
'Woman with a Cat', 'Mourning Woman'], dtype=object)basic stats¶
df.describe()pulling out rows¶
df[100:105]create new dfs from columns¶
titles = df['title'].valueslen(titles)500type(titles)numpy.ndarraysorting data¶
Using .value_counts() and.sort_values()
df.value_counts('title')title
Terracotta statuette of a woman 31
Woman 20
Terracotta head of a woman 18
Portrait of a Woman 9
Terracotta statuette of a draped woman 9
..
Marble head of a goddess 1
Marble head of a girl from a small statue 1
Marble grave stele of a young woman and servant 1
Marble grave stele of a woman 1
Young woman holding libation cup 1
Name: count, Length: 332, dtype: int64df.value_counts('department')department
Greek and Roman Art 255
Egyptian Art 88
European Sculpture and Decorative Arts 40
European Paintings 39
Modern and Contemporary Art 24
The American Wing 9
Drawings and Prints 8
Medieval Art 8
Asian Art 7
Robert Lehman Collection 5
Islamic Art 3
Photographs 2
The Cloisters 2
Ancient Near Eastern Art 1
The Michael C. Rockefeller Wing 1
Name: count, dtype: int64df.value_counts('medium')medium
Terracotta 164
Marble 43
Bronze 38
Oil on canvas 34
Hard-paste porcelain 15
...
Hard-paste porcelain, gilt-bronze 1
Hard-paste biscuit porcelain 1
Hanging scroll; ink, color, and gold on silk 1
Greywacke 1
limestone, paint 1
Name: count, Length: 128, dtype: int64df.value_counts('artistDisplayName')artistDisplayName
Edgar Degas 14
Imperial Porcelain Manufactory, St. Petersburg 8
Pablo Picasso 7
Johannes Vermeer 3
Willem de Kooning 3
..
Giovanni Battista Gaulli (Il Baciccio) 1
Giacomo Ceruti 1
Georges Braque 1
Gaston Lachaise 1
Woman's Liberty Loan Committee 1
Name: count, Length: 90, dtype: int64df.sort_values('accessionYear')filtering data¶
You can filter data through conditional statements using equivalence operator ==
# prints out a series that fulfills the condition
df['title'] == 'Woman'0 True
1 True
2 False
3 True
4 True
...
495 False
496 False
497 False
498 False
499 False
Name: title, Length: 500, dtype: bool# saves the series to a variable
woman = df['title'] == 'Woman'# you have a series
type(woman)pandas.core.series.Series# and with df[] you have a dataframe
type(df[woman])pandas.core.frame.DataFramedf[woman].info()<class 'pandas.core.frame.DataFrame'>
Index: 20 entries, 0 to 63
Data columns (total 42 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 objectID 20 non-null float64
1 isHighlight 20 non-null float64
2 accessionNumber 20 non-null object
3 accessionYear 20 non-null float64
4 isPublicDomain 20 non-null float64
5 primaryImage 8 non-null object
6 additionalImages 20 non-null object
7 constituents 17 non-null object
8 department 20 non-null object
9 objectName 20 non-null object
10 title 20 non-null object
11 culture 0 non-null object
12 period 0 non-null object
13 dynasty 0 non-null object
14 reign 0 non-null object
15 artistDisplayName 17 non-null object
16 artistDisplayBio 16 non-null object
17 artistNationality 14 non-null object
18 artistBeginDate 16 non-null object
19 artistEndDate 16 non-null object
20 artistGender 1 non-null object
21 artistWikidata_URL 13 non-null object
22 artistULAN_URL 14 non-null object
23 objectDate 20 non-null object
24 objectBeginDate 20 non-null float64
25 objectEndDate 20 non-null float64
26 medium 20 non-null object
27 dimensions 20 non-null object
28 measurements 18 non-null object
29 creditLine 20 non-null object
30 geographyType 0 non-null object
31 city 0 non-null object
32 state 0 non-null object
33 county 0 non-null float64
34 country 1 non-null object
35 region 0 non-null object
36 objectURL 20 non-null object
37 tags 17 non-null object
38 objectWikidata_URL 4 non-null object
39 isTimelineWork 20 non-null float64
40 GalleryNumber 1 non-null object
41 message 0 non-null object
dtypes: float64(8), object(34)
memory usage: 6.7+ KB
making a df from highlighted works¶
highlights = df['isHighlight'] == 1.0df[highlights].head()df[highlights].info()<class 'pandas.core.frame.DataFrame'>
Index: 37 entries, 22 to 461
Data columns (total 42 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 objectID 37 non-null float64
1 isHighlight 37 non-null float64
2 accessionNumber 37 non-null object
3 accessionYear 37 non-null float64
4 isPublicDomain 37 non-null float64
5 primaryImage 29 non-null object
6 additionalImages 37 non-null object
7 constituents 19 non-null object
8 department 37 non-null object
9 objectName 37 non-null object
10 title 37 non-null object
11 culture 14 non-null object
12 period 18 non-null object
13 dynasty 4 non-null object
14 reign 4 non-null object
15 artistDisplayName 19 non-null object
16 artistDisplayBio 18 non-null object
17 artistNationality 18 non-null object
18 artistBeginDate 18 non-null object
19 artistEndDate 18 non-null object
20 artistGender 7 non-null object
21 artistWikidata_URL 18 non-null object
22 artistULAN_URL 18 non-null object
23 objectDate 37 non-null object
24 objectBeginDate 37 non-null float64
25 objectEndDate 37 non-null float64
26 medium 37 non-null object
27 dimensions 37 non-null object
28 measurements 37 non-null object
29 creditLine 37 non-null object
30 geographyType 7 non-null object
31 city 1 non-null object
32 state 0 non-null object
33 county 0 non-null float64
34 country 5 non-null object
35 region 4 non-null object
36 objectURL 37 non-null object
37 tags 36 non-null object
38 objectWikidata_URL 34 non-null object
39 isTimelineWork 37 non-null float64
40 GalleryNumber 28 non-null object
41 message 0 non-null object
dtypes: float64(8), object(34)
memory usage: 12.4+ KB
using str.contains() to filter string data¶
courbet = df['artistDisplayName'].str.contains('Courbet', na=False)df[courbet]# can use the column syntax to pull the titles from this new df
df[courbet]['title']42 Woman with a Parrot
70 Woman in a Riding Habit (L'Amazone)
82 The Woman in the Waves
Name: title, dtype: objectplotting data¶
df.keys()Index(['objectID', 'isHighlight', 'accessionNumber', 'accessionYear',
'isPublicDomain', 'primaryImage', 'additionalImages', 'constituents',
'department', 'objectName', 'title', 'culture', 'period', 'dynasty',
'reign', 'artistDisplayName', 'artistDisplayBio', 'artistNationality',
'artistBeginDate', 'artistEndDate', 'artistGender',
'artistWikidata_URL', 'artistULAN_URL', 'objectDate', 'objectBeginDate',
'objectEndDate', 'medium', 'dimensions', 'measurements', 'creditLine',
'geographyType', 'city', 'state', 'county', 'country', 'region',
'objectURL', 'tags', 'objectWikidata_URL', 'isTimelineWork',
'GalleryNumber', 'message'],
dtype='object')df.plot()<Axes: >
df.plot(kind = 'bar')<Axes: >
df.value_counts('department').plot(kind = 'bar')<Axes: xlabel='department'>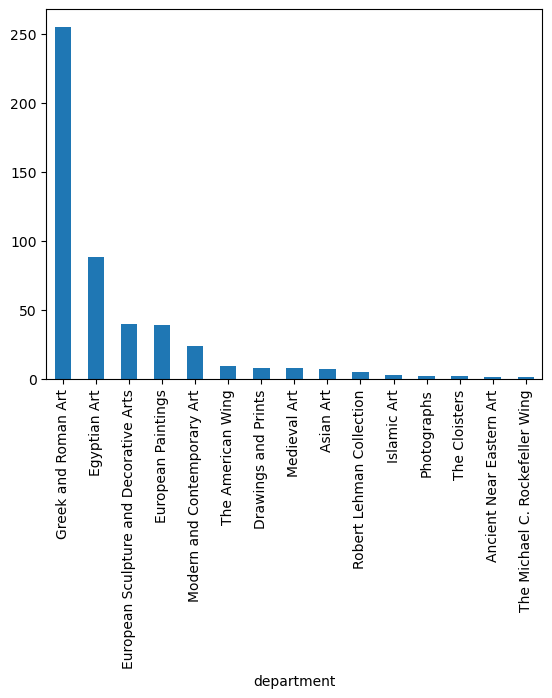
df.value_counts('department').plot(kind = 'pie')<Axes: ylabel='count'>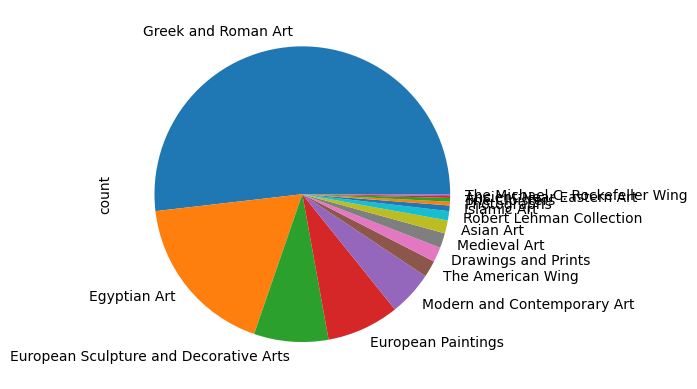
df.value_counts('title').plot(kind = 'bar')<Axes: xlabel='title'>
df.value_counts('title').nlargest(10).plot(kind = 'bar')<Axes: xlabel='title'>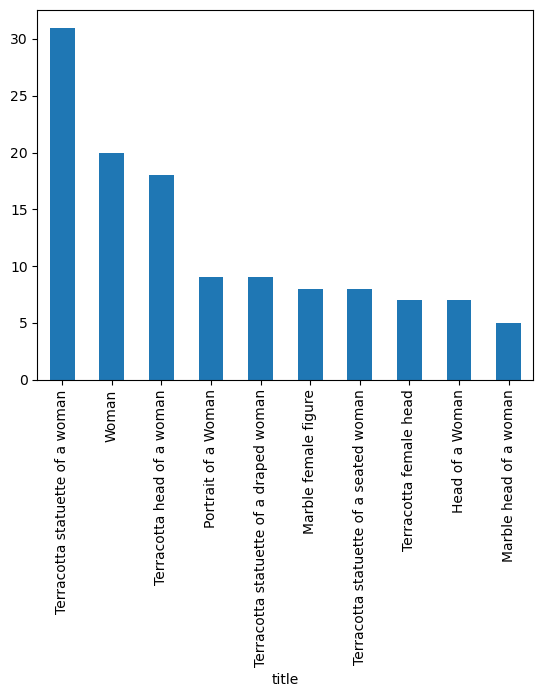
df.value_counts('artistDisplayName').nlargest(12).plot(kind = 'bar')<Axes: xlabel='artistDisplayName'>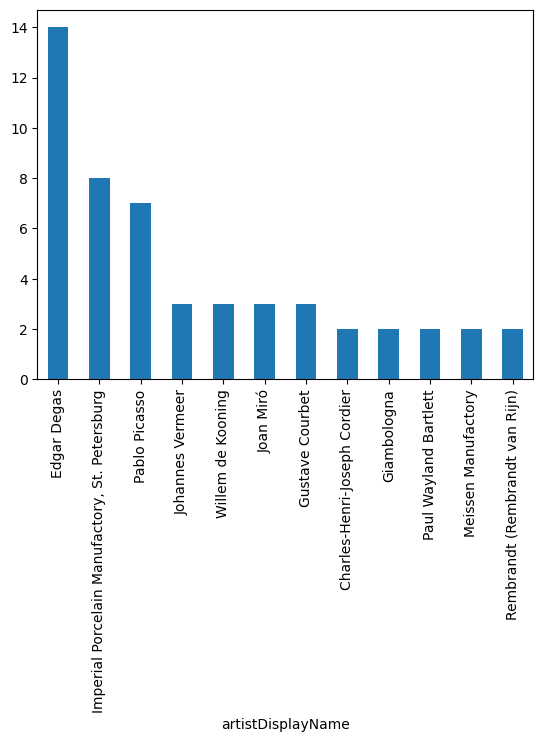
df.value_counts('artistDisplayName').nlargest(10).plot(kind='barh', ylabel='Artist Name', title='Works of "Women" at the MET')<Axes: title={'center': 'Works of "Women" at the MET'}, ylabel='Artist Name'>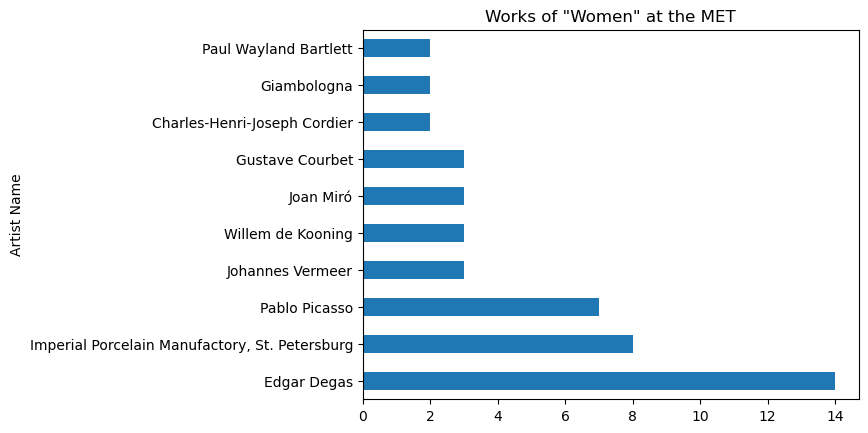
Other plotting libraries:
Plotly - for creating interactive, web-based visualizations, supporting over 40 chart types including 3D plots and contour plots. Known for interactivity and dynamic visualizations.
Seaborn - offers built-in themes, color palettes and functions to easily create plots like bar charts, histograms, scatterplots and more. Known for simpler syntax.