NLTK: cleaning part two#
# On Jupyter - run this cell
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# on Colab -- run this cell
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('omw-1.4')
nltk.download('punkt')
[nltk_data] Downloading package stopwords to
[nltk_data] /Users/caladof/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package wordnet to /Users/caladof/nltk_data...
[nltk_data] Package wordnet is already up-to-date!
[nltk_data] Downloading package omw-1.4 to /Users/caladof/nltk_data...
[nltk_data] Package omw-1.4 is already up-to-date!
[nltk_data] Downloading package punkt to /Users/caladof/nltk_data...
[nltk_data] Package punkt is already up-to-date!
True
nltk personals corpus#
# import our list of books from the NLTK library
from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
---------------------------------------------------------------------------
LookupError Traceback (most recent call last)
File ~/anaconda3/lib/python3.11/site-packages/nltk/corpus/util.py:84, in LazyCorpusLoader.__load(self)
83 try:
---> 84 root = nltk.data.find(f"{self.subdir}/{zip_name}")
85 except LookupError:
File ~/anaconda3/lib/python3.11/site-packages/nltk/data.py:583, in find(resource_name, paths)
582 resource_not_found = f"\n{sep}\n{msg}\n{sep}\n"
--> 583 raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource gutenberg not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('gutenberg')
For more information see: https://www.nltk.org/data.html
Attempted to load corpora/gutenberg.zip/gutenberg/
Searched in:
- '/Users/caladof/nltk_data'
- '/Users/caladof/anaconda3/nltk_data'
- '/Users/caladof/anaconda3/share/nltk_data'
- '/Users/caladof/anaconda3/lib/nltk_data'
- '/usr/share/nltk_data'
- '/usr/local/share/nltk_data'
- '/usr/lib/nltk_data'
- '/usr/local/lib/nltk_data'
**********************************************************************
During handling of the above exception, another exception occurred:
LookupError Traceback (most recent call last)
Cell In[3], line 3
1 # import our list of books from the NLTK library
----> 3 from nltk.book import *
File ~/anaconda3/lib/python3.11/site-packages/nltk/book.py:27
24 print("Type the name of the text or sentence to view it.")
25 print("Type: 'texts()' or 'sents()' to list the materials.")
---> 27 text1 = Text(gutenberg.words("melville-moby_dick.txt"))
28 print("text1:", text1.name)
30 text2 = Text(gutenberg.words("austen-sense.txt"))
File ~/anaconda3/lib/python3.11/site-packages/nltk/corpus/util.py:121, in LazyCorpusLoader.__getattr__(self, attr)
118 if attr == "__bases__":
119 raise AttributeError("LazyCorpusLoader object has no attribute '__bases__'")
--> 121 self.__load()
122 # This looks circular, but its not, since __load() changes our
123 # __class__ to something new:
124 return getattr(self, attr)
File ~/anaconda3/lib/python3.11/site-packages/nltk/corpus/util.py:86, in LazyCorpusLoader.__load(self)
84 root = nltk.data.find(f"{self.subdir}/{zip_name}")
85 except LookupError:
---> 86 raise e
88 # Load the corpus.
89 corpus = self.__reader_cls(root, *self.__args, **self.__kwargs)
File ~/anaconda3/lib/python3.11/site-packages/nltk/corpus/util.py:81, in LazyCorpusLoader.__load(self)
79 else:
80 try:
---> 81 root = nltk.data.find(f"{self.subdir}/{self.__name}")
82 except LookupError as e:
83 try:
File ~/anaconda3/lib/python3.11/site-packages/nltk/data.py:583, in find(resource_name, paths)
581 sep = "*" * 70
582 resource_not_found = f"\n{sep}\n{msg}\n{sep}\n"
--> 583 raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource gutenberg not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('gutenberg')
For more information see: https://www.nltk.org/data.html
Attempted to load corpora/gutenberg
Searched in:
- '/Users/caladof/nltk_data'
- '/Users/caladof/anaconda3/nltk_data'
- '/Users/caladof/anaconda3/share/nltk_data'
- '/Users/caladof/anaconda3/lib/nltk_data'
- '/usr/share/nltk_data'
- '/usr/local/share/nltk_data'
- '/usr/lib/nltk_data'
- '/usr/local/lib/nltk_data'
**********************************************************************
text8: the personals corpus#
# check out text8, the personals ads, first 20 words
text8[:20]
['25',
'SEXY',
'MALE',
',',
'seeks',
'attrac',
'older',
'single',
'lady',
',',
'for',
'discreet',
'encounters',
'.',
'35YO',
'Security',
'Guard',
',',
'seeking',
'lady']
# how to find the length of the dataset, use len()
len(text8)
4867
# check the most frequent words, using nltk method "Frequency
# Distribution", that measures word frequencies
# first import the FreqDist class
from nltk import FreqDist
# then check the most common 15 words
FreqDist(text8).most_common(20)
[(',', 539),
('.', 353),
('/', 110),
('for', 99),
('and', 74),
('to', 74),
('lady', 68),
('-', 66),
('seeks', 60),
('a', 52),
('with', 44),
('S', 36),
('ship', 33),
('&', 30),
('relationship', 29),
('fun', 28),
('in', 27),
('slim', 27),
('build', 27),
('o', 26)]
# notice that the text is not cleaned, since it's counting
# punctuation and stopwords.
# We need to write a loop that remove stopwords and punctuation
stops = stopwords.words('english')
personals_clean = [] # creating an empty list, to put new words in
for word in text8: # picking out each word in text8
if word.isalpha(): # checking if that word is in the alphabet
if word not in stops: # checking if that word is in stops
personals_clean.append(word.lower()) # adding to our list
# check the first 20 words -- we have a cleaner dataset now
personals_clean[:20]
['sexy',
'male',
'seeks',
'attrac',
'older',
'single',
'lady',
'discreet',
'encounters',
'security',
'guard',
'seeking',
'lady',
'uniform',
'fun',
'times',
'yo',
'single',
'dad',
'sincere']
# create a frequency distribution, the results are much better
# than before
FreqDist(personals_clean).most_common(20)
[('lady', 88),
('seeks', 72),
('male', 42),
('s', 36),
('looking', 34),
('ship', 33),
('slim', 33),
('fun', 31),
('attractive', 29),
('relationship', 29),
('build', 27),
('good', 26),
('seeking', 25),
('non', 25),
('smoker', 23),
('n', 23),
('guy', 22),
('honest', 22),
('i', 22),
('movies', 22)]
# right now, our data is in a list
type(personals_clean)
list
# let's try some nltk methods that we know, like dispersion_plot(),
# similar(), concordance()
# In order to use those methods, we first create an NLTK object
# for our text
personals = nltk.Text(personals_clean)
# now we have an nltk.text.Text type of object, which is good
type(personals)
nltk.text.Text
# check similar words for our top word in the FreqDist, 'lady'
personals.similar('lady')
seeks fem female looking women someone woman short
# create a concordance for 'lady'
personals.concordance('lady')
Displaying 25 of 88 matches:
sexy male seeks attrac older single lady discreet encounters security guard s
et encounters security guard seeking lady uniform fun times yo single dad sinc
en s e tall seeks working single mum lady fship rship nat open yr old outgoing
en phone fun ready play affectionate lady sought generous guy mutual fulfillme
afes beach c seeks honest attractive lady european background without children
lly secure children seeks attractive lady children i enjoy beach sports music
s walks beach single would like meet lady friendship view relationship austral
er with son living seeks nice caring lady likes children permanent lationship
al person life looking caring honest lady friendship relationship businessman
relationship businessman ish looking lady non smoker taller business outlook t
h modern outlook cuddly full figured lady plus sought australian gent early fi
g camping music love kids am looking lady similar interests aged friendship po
ependant standing mid looking classy lady wants retain privacy still retain in
inker fit active seeking slim medium lady friendship relationship limestone co
et attractive non smoking fun loving lady friendship view permanent relationsh
s dining etc outgoing guy late seeks lady size unimportant fun good times reti
od times retired gent like meet slim lady long term caravan travel heading dar
quiet nights seeks employed year old lady relationship clare barossa region no
financially secure seeks australian lady genuine relationship single mum welc
t long term relationship slim petite lady age years yo guy slim seeks yo femal
tall guy would like meet attractive lady long term relationship central victo
e dad teen daughters looking special lady fit healthy self emp tradesman ns se
tradesman ns seeks indian sri lankan lady ns olive dark complexion f dship pos
ker looking fship rship asian indian lady years romantic sexy country guy ns s
sexy country guy ns seeks similar ns lady fun friendship well dressed emotiona
# dispersion_plot() checks where certain words appear
personals.dispersion_plot(['lady', 'male', 'fun'])
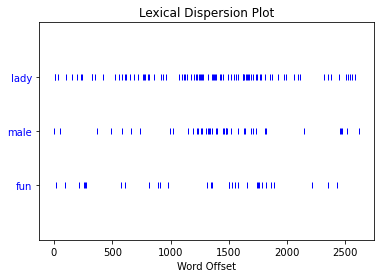
# collocations() checks words that frequently go together
personals.collocations()
non smoker; would like; like meet; age open; social drinker; medium
build; quiet nights; long term; sense humour; med build; easy going;
nights home; poss rship; smoker social; financially secure; fship
poss; fun times; weekends away; single dad; similar interests
# common_contexts([]) checks the immediate words (context) surrounding
# our target word
personals.common_contexts(['lady'])
looking_non asian_sought seeks_age seeks_casual married_discreet
seeks_r single_discreet seeking_uniform mum_fship affectionate_sought
attractive_european attractive_children meet_friendship caring_likes
honest_friendship figured_plus looking_similar classy_wants
medium_friendship loving_friendship
patterns and research questions#
What patterns do you see emerging from your exploration? Use methods like: similar(), concordance(), collocations(), dispersion_plot(), common_contexts()
Results:
adjectives like ‘slim’, ‘fun’ are more common than ‘classy’
seems like it’s more men seeking out women, ‘common_contexts’
text5: the chat corpus#
# we are going to check out text5, the chat corpus
# creating a slice to take a peek at the data
text5[:10]
['now', 'im', 'left', 'with', 'this', 'gay', 'name', ':P', 'PART', 'hey']
# checking the end of the data
text5[-20:]
['out',
'U34',
'?',
'lol',
'hi',
'U3',
'JOIN',
'Hi',
',',
'U197',
'.',
'Not',
'that',
'I',
'know',
'of',
',',
'U98',
'Uh',
'.']
# making a Frequency Distribution to see most common words
FreqDist(text5).most_common(20)
[('.', 1268),
('JOIN', 1021),
('PART', 1016),
('?', 737),
('lol', 704),
('to', 658),
('i', 648),
('the', 646),
('you', 635),
(',', 596),
('I', 576),
('a', 568),
('hi', 546),
('me', 415),
('...', 412),
('is', 372),
('..', 361),
('in', 357),
('ACTION', 346),
('!', 342)]
# it seems like there's a lot of stopwords and punctuation here, which we
# want to clean
# function for cleaning the text
def clean(text):
stops = stopwords.words('english') # creating a list of stopwords
clean = [] # creating an empty list, to put new words in
for word in text: # picking out each word in text5
if word.isalpha(): # checking if in alphabet
if word not in stops: # checking if stopword
clean.append(word.lower()) # adding to list
return clean
# calling the function
cleaned = clean(text5)
# we can see that the stopwords, punctuation, and uppercase letters have been removed
cleaned[:10]
['im', 'left', 'gay', 'name', 'part', 'hey', 'everyone', 'ah', 'well', 'nick']
cleaned[-20:]
['hi',
'join',
'fine',
'gurls',
'hurr',
'pm',
'find',
'hi',
'were',
'one',
'nicks',
'kicked',
'lol',
'hi',
'join',
'hi',
'not',
'i',
'know',
'uh']
# now our frequency distribution is more informative
# though it's still not a very rich dataset
FreqDist(cleaned).most_common(20)
[('part', 1022),
('join', 1021),
('lol', 822),
('hi', 656),
('i', 576),
('action', 347),
('hey', 292),
('u', 204),
('like', 160),
('im', 149),
('pm', 149),
('chat', 146),
('good', 132),
('lmao', 128),
('wanna', 110),
('ok', 106),
('know', 104),
('get', 104),
('room', 103),
('ya', 100)]
text.similar('lmao')
part join hi lol hey i yeah everyone haha wb right well still ok yes
room hahaha oh ppl hello
text.concordance('lmao')
Displaying 25 of 128 matches:
right hi fucking hot thought hi late lmao ahah iamahotniplickme part hi ny act
wow twice i impressed part hiya room lmao im doin alright thanks omg finger de
ioned honey depends hi ca babies yep lmao action laughs part fiance know handl
es me love join lol u know jerkettes lmao co well girls didnts say anithing wr
g wrong see eyes lol fiance jerketts lmao wtf yah i know honey join girl jerk
n ug shit il get u cheap flight hell lmao bbl maybe part lol lol hahah got ass
ee lmfao join action goes wash hands lmao i innocent lies lmao check record lo
goes wash hands lmao i innocent lies lmao check record lol lick em old r u lol
d r u lol way lie mmhmm polite calls lmao u yo may om action lix ummm lol lol
going bed want hot sexy dreams bite lmao darling guy action wishes someone wo
art hahah hey funny way chase people lmao part watch ty hey part bored guys wa
art hey put untouchable list im good lmao r u hehe hows bout u good hear knows
orror scopes lol nice horrified hehe lmao even join well going talk later byb
i take advice lol client suffer join lmao i always days late i finish meeting
d hi hey good ques always lol strong lmao strait lol join shakin way i like oh
ing dumb asses wont chat ya ok guess lmao go figure finally someone figured wo
i thinking orgy around lol orgy lol lmao wow one word people easy lol lol fun
ol funny part join getting back orgy lmao whats bye part lets play naked twist
pissed sure lol hello oopps i meant lmao hey anyone pm room ya gotta watch ma
everyone yes hey oh meant lover lol lmao go figure think yeah cuz many lmao g
l lmao go figure think yeah cuz many lmao gotta try seriously meant lol sexy i
lol keep around gotta stick sometime lmao lol party hair like knockin door i b
door i bet prob party hair seriously lmao join thanks sexy bonus point life lo
part right join part perked ya right lmao steel ok say cant creative enough co
come better line ya horny stay away lmao ummm yeah sheepishly dang didnt even
Group challenge#
Choose one text from the nltk.book list. Use from nltk.book import * to call up the list.
Then, using NLTK methods we know, like similar(), concordance(), distribution_plot([]), do some analysis on these lists.
What patterns do you see emerging from your exploration? Be ready to share with the class.
text2
<Text: Sense and Sensibility by Jane Austen 1811>
# one of the words in the title is associated with a character, 'Marianne'
text2.similar('sense')
sister that side as opinion mother means time marianne wish want part
sweetness resolution and family property manner life but
text2.similar('sensibility')
this it time conduct mind company family man her house heart him
mother that way living year income disposition marianne